





From Chatbots to AI Assistants: Building Technology That Truly Serves People
Navigation

At GLOBSEC’s “Women in AI and Innovation” debate in Bratislava, I had the opportunity to share Alistiq’s vision for the future of artificial intelligence. The conversation centered on a critical distinction that defines our work: the difference between a chatbot that simply answers questions—often incorrectly, through “hallucinations”—and an intelligent assistant that actively solves problems, asks clarifying questions on its own, and doesn’t make mistakes.
The Challenge of Personal Data in a Surveillance Economy
Do we want to live in what Harvard professor Shoshana Zuboff calls “the age of surveillance capitalism”? Her warning is stark: this model undermines personal autonomy and erodes democracy. The alternative is a human-centric approach to personal data, championed by initiatives like MyData.org. This means putting users at the center with personal data management tools, enabling data sharing only with consent, avoiding central data repositories, and building new infrastructure for interoperability and mutual trust. Sir Tim Berners-Lee’s Solid Project represents exactly this kind of correction—users control which entities and apps access their data, stored in personal “Pods” with full permissioning controls.
“Surveillance capitalism is undermining personal autonomy and eroding democracy.” — Shoshana Zuboff, Harvard Business School
Why Healthcare Data Is So Hard to Get Right
Electronic Health Records present enormous challenges for AI applications. This data is the output of complex processes and decision-making from various environments, characterized by high dimensionality, noise, heterogeneity, sparseness, incompleteness, random errors, and systematic biases. Pioneering work like “Deep Patient” from Mount Sinai—which used EHRs from 700,000 patients and 200 million data entries to predict future health outcomes—shows what’s possible. But getting there requires sophisticated approaches: transforming symbolic graph data into numeric representations, using ontologies like FHIR RDF for healthcare domains, and building neural networks that can capture hierarchical patterns in this messy, real-world data.
Building Assistants That Actually Help
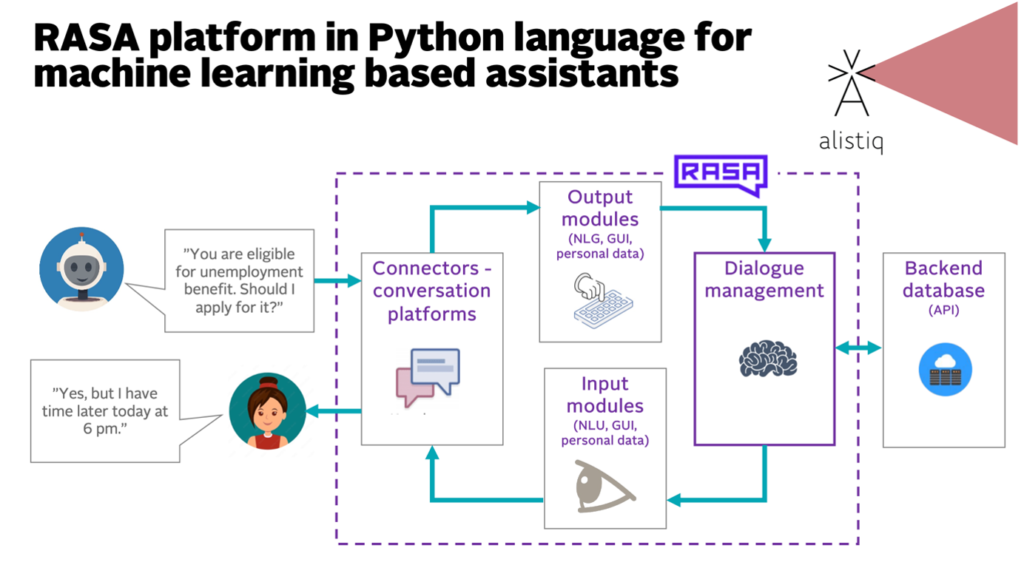
The RASA platform represents the architecture we need for machine learning-based assistants that go beyond simple question-answering. These systems integrate conversation connectors, dialogue management, natural language understanding and generation, and crucially—access to personal data through backend APIs. Imagine an assistant that tells you: “You are eligible for unemployment benefit. Should I apply for it?” This requires the system to understand your situation, connect to relevant data sources, and take action on your behalf—all while keeping you in control.
Graph Data: The Foundation for Personalized Services
Making this work requires transforming data from various sources into structured graph formats using W3C RDF standards. A person’s information—their relationships, birth dates, addresses—becomes a connected knowledge graph that an AI assistant can query and reason over. This isn’t about surveillance; it’s about giving people tools that understand their context and can genuinely help, with full transparency and consent.
The future of AI isn’t about building smarter chatbots. It’s about building assistants that respect our data, understand our needs, and work for us—not the other way around.
This blog is based on my contribution to this event below